Berdasarkan UU ITE dan KUHP, segala bentuk perjudian online termasuk slot dianggap ilegal.
Pengguna maupun penyedia situs bisa dikenai sanksi hukum, mulai dari denda besar hingga hukuman penjara.
Rentan Penipuan
Banyak situs “slot gacor” palsu yang hanya menarik deposit tanpa benar-benar membayar kemenangan.
Data pribadi, nomor rekening, dan identitas bisa disalahgunakan.
Kecanduan & Kerugian Finansial
Sistem permainan slot dirancang membuat pemain terus bermain.
Banyak orang terjebak karena berharap “balik modal”, padahal peluang menang sangat kecil.
🧩 Alternatif Aman & Legal Buat Hiburan
Kalau kamu suka sensasi dan visual game slot, kamu tetap bisa menikmatinya lewat cara yang aman:
🎮 Slot Demo Gratis (Legal)
Main di mode demo PG Soft atau Pragmatic Play di situs resmi provider.
Nggak perlu login, deposit, atau uang asli — semua saldo virtual.
Aman, bebas risiko, dan tetap seru.
🕹️ Game Arcade & Casual Legal
Game seperti Coin Master, Match-3, atau Lucky Spin di Play Store mirip slot tapi tanpa unsur judi.
Bisa dimainkan santai, bahkan kadang bisa tukar hadiah dalam game (bukan uang asli).
📱 Platform Game Legal
Gunakan platform seperti Steam, Google Play Games, atau App Store buat cari game dengan tema kasino tapi tanpa taruhan uang asli.
💬 Kesimpulan
Kalau kamu cuma cari hiburan dan sensasi spin, slot demo gratis udah cukup banget. Kamu bisa belajar pola, rasain bonus, dan nikmatin gameplay-nya tanpa risiko hukum atau kehilangan uang.Agen234
L’ingénierie d’externalisation peut libérer l’échelle, la rentabilité et l’accès aux talents mondiaux. Mais céder certaines parties de votre pile technologique introduit également des risques : qualité inférieure, vulnérabilités en matière de sécurité, désalignement. En 2025, alors que les menaces et la complexité augmentent, vous ne pouvez pas vous permettre de perdre le contrôle de l’assurance qualité et de la sécurité. Voyons comment garder le contrôle.
1. Pourquoi l’assurance qualité et la sécurité doivent être de premier ordre en matière d’externalisation
Lorsque vous externalisez une partie de votre développement, vous déléguez non seulement du travail mais aussi de l’exposition :
Même de petites failles de sécurité ou des défauts de qualité peuvent causer des dommages importants (réputation, finances, confiance des utilisateurs).
Souvent, vous n’avez pas une visibilité complète sur la manière exacte dont le fournisseur écrit, teste ou sécurise le code.
La barrière distante/distribuée peut exacerber les problèmes de communication, les retards ou les défauts subtils.
Les technologies sont plus complexes (microservices, API, cloud, IA), de sorte que les charges de sécurité et d’assurance qualité augmentent.
Dans ces conditions, l’externalisation sans un régime de qualité et de sécurité solide est trop risquée.
2. Piliers clés : où vous devez garder le contrôle
Voici les principaux domaines dans lesquels vous devez conserver un pouvoir de décision ou une surveillance très étroite :
2.1 Définir dès le départ les normes de qualité et de sécurité
Avant qu’un code ne soit écrit, vous devez définir et documenter normes explicites de qualité et de sécurité. par exemple : • Couverture de tests ciblée (unitaire, intégration, de bout en bout) • Seuils de défauts (critique / élevé / moyen) • Limites de performances/latences • Exigences de sécurité (par exemple cryptage, OWASP, règles de codage sécurisées)
Ces normes doivent faire partie du contrat/SLA/énoncé des travaux.
Utilisez des métriques mesurables (par exemple < 0,5 % de défauts critiques, 85 % de couverture de code, aucune vulnérabilité de haute gravité lors de l'analyse)
De nombreuses listes de bonnes pratiques en matière d’assurance qualité mettent l’accent sur l’engagement précoce de l’assurance qualité et la définition de mesures de qualité.
L’établissement de normes dès le départ garantit que tout le monde sait à quoi ressemble le « bien ».
2.2 Sélection et vérification des fournisseurs
Choisissez des fournisseurs qui ont déjà Assurance qualité et maturité en matière de sécurité (outils, processus, certifications).
Demandez des études de cas antérieures mettant en avant la qualité et la sécurité (par exemple, tests d’intrusion, conformité)
Vérifiez leur pile technologique, leur chaîne d’outils et leur expérience dans les domaines sensibles en matière de sécurité
Vérifier leurs politiques de sécurité : NDA, contrôle d’accès, vérification des antécédents, cyberhygiène
Un guide sur l’externalisation de l’assurance qualité suggère des fournisseurs exigeants dotés de politiques de cybersécurité strictes, de cryptage, de contrôles d’accès et d’audits périodiques.
Ne vous contentez pas de choisir le coût le plus bas, choisissez celui en qui vous pouvez avoir confiance.
2.3 Gouvernance, surveillance et audit
Maintenir un couche de gouvernance — une petite équipe ou une personne de votre côté qui examine les livrables critiques, les journaux d’audit et les rapports de sécurité.
Exiger droits de vérification — la possibilité d’inspecter le code du fournisseur, les journaux, l’environnement et les outils de sécurité.
Conduire audits réguliers (trimestriel ou plus fréquent) du code, de l’infrastructure, des contrôles d’accès, des vulnérabilités de dépendance.
Insérer portes / jalons de qualité dans votre processus de livraison : le code du fournisseur doit satisfaire aux métriques et aux contrôles de sécurité avant la fusion ou la publication.
Utilisez occasionnellement des tests d’intrusion externes ou tiers ou un audit de code comme contrôles impartiaux.
La gouvernance garantit que vous n’êtes pas aveugle à ce qui est livré.
2.4 Outillage automatisé, CI/CD et intégration
S’assurer que le travail du fournisseur est intégré dans ton Pipeline CI/CD ou équivalent. Cela vous permet d’exécuter vos propres tests, analyses de sécurité et contrôles de qualité du code.
Utilisez l’analyse statique automatisée, le peluchage et les scanners de sécurité (par exemple SonarQube, SAST, DAST) dans le cadre des pipelines de vérification de code.
Automatisez les tests (unitaires, de régression, d’intégration) afin que la qualité soit évaluée en permanence.
Comme le montrent les meilleures pratiques d’assurance qualité, l’application précoce de l’automatisation et l’intégration à CI/CD permettent de maintenir la cohérence et de réduire la surveillance manuelle.
Traitez les modifications de code du fournisseur de la même manière qu’en interne : même pipeline, mêmes contrôles.
Cela réduit les erreurs humaines et garantit que les normes sont appliquées par programme.
2.5 Pratiques de développement sécurisées et sécurité dès la conception
Exiger que le vendeur adopte sécurisé dès la conception réflexion : intégrez la sécurité dès la phase de conception, et non après coup.
Exigez des pratiques telles que la validation des entrées, le moindre privilège, la défense en profondeur et les valeurs par défaut sécurisées.
Exiger des révisions de code axées sur la sécurité, la modélisation des menaces et les contrôles de vulnérabilité des dépendances.
Pour les microservices/systèmes distribués, assurez-vous que le fournisseur suit les meilleures pratiques de sécurité des microservices (par exemple, expiration des jetons, TLS mutuel, limites de confiance zéro). (La sécurité des microservices est particulièrement délicate ; voir les défis des praticiens dans la littérature).
Appliquer un Cycle de vie du développement logiciel (SDLC) qui comprend des contrôles de sécurité à chaque phase (exigences, conception, codage, tests, déploiement).
Exécutez périodiquement des tests d’intrusion, des tests de fuzz, exécutez des analyses OWASP ou spécifiques à un domaine.
Cela permet de minimiser le risque de sécurité du code externalisé.
2.6 Communication, transparence et rapports
Maintenir statut régulier, métriques, tableaux de bord: taux de défauts, couverture du code, résultats de l’analyse de sécurité, taux de réussite aux tests.
Utilisez des outils/plateformes partagés (Jira, GitHub, tableaux de bord) où vous pouvez voir les progrès et les problèmes.
Exiger du vendeur qu’il produise rapports d’incidents / violationsanalyses des causes profondes, post-mortems.
Insister sur journaux de modifications transparents, journaux d’accès, pistes d’audit pour le déploiement, l’infrastructure, l’accès aux données.
Les rétrospectives/revues partagées aident à découvrir les lacunes et à s’améliorer continuellement.
La transparence est votre visibilité sur la qualité et la sécurité.
2.7 Escalade, réponse aux incidents et responsabilité
Définir accords de niveau de service (SLA) qui incluent des clauses de qualité et de sécurité, ainsi que des sanctions en cas de violation.
Définir chemins d’escalade: qui vous contactez si un problème critique est détecté, à quelle vitesse il doit être résolu.
Spécifier responsabilité: qui paie les violations, les pertes de données, les retouches.
Inclure clauses de sortie / code séquestre / transfert: assurez-vous d’obtenir le code, la documentation et les actifs si vous résiliez.
Planifier pour accès médico-légal: le fournisseur doit fournir des journaux, des données et un accès au code pour vous aider à répondre aux incidents de sécurité.
Cela garantit que vous êtes protégé en cas de problème.
3. Pièges et erreurs courants à éviter
Lors de l’externalisation, de nombreuses entreprises tombent dans ces pièges :
Définir de vagues attentes en matière de qualité ou de sécurité : « il suffit de le sécuriser ».
En supposant que le fournisseur suivra automatiquement vos normes, sans vérification.
Ne pas intégrer le code du fournisseur dans vos pipelines – faire du code du fournisseur une « boîte noire ».
Contrôle d’accès inadéquat ou privilèges excessifs sur les comptes des fournisseurs.
Aucun droit d’audit ni aucun examen de sécurité périodique.
Surveiller les contraintes de conformité/réglementation (par exemple RGPD, HIPAA), en particulier lorsque le fournisseur se trouve dans une juridiction différente.
Négliger le support après le transfert, le transfert de connaissances ou le dépôt de code.
En partant du principe que faible coût est synonyme de qualité, les retouches ou les défauts cachés coûtent souvent plus cher en aval.
Les éviter vous aide à garder le contrôle.
4. Un cadre pratique/une feuille de route que vous pouvez appliquer
Voici une feuille de route pratique étape par étape que vous pouvez appliquer à vos projets d’ingénierie externalisés :
Définir et documenter les normes de qualité/sécurité avant de sélectionner le fournisseur
Connaître les fournisseurs sur la maturité QA/sécurité, les audits passés, les références
Contrat avec les SLA, droits d’audit, escalade, responsabilité, clauses de transfert
Pilote d’abord — exécuter un petit module sous surveillance totale d’assurance qualité/sécurité
Intégrer code du fournisseur dans vos pipelines et votre chaîne d’outils
Déployez des contrôles de qualité, des contrôles automatisés, des analyses de code et des examens de sécurité
Gouvernance et audits — revues continues, tests d’intrusion, audits de code
Suivi des métriques / tableaux de bord / transparence
Former conjointement le fournisseur — partager les bonnes pratiques, l’hygiène, le codage sécurisé
Plan de transfert/sortie — code, documents, transferts, séquestre
Cette feuille de route vous aide à faire évoluer progressivement le contrôle sans surcharge ni microgestion.
5. Tendances et considérations futures
Pour 2025 et plus, voici quelques développements et éléments à surveiller :
Une plus grande adoption de Analyse qualité et sécurité assistée par l’IA (détection automatisée de vulnérabilités, suggestion de code)
Différenciation des fournisseurs via certifications de maturité et de conformité en matière de sécurité (SOC2, ISO, O-TTPS)
Plus modèles de gouvernance hybridesoù le client conserve une petite équipe de surveillance interne
Réglementation croissante concernant les données, la confidentialité et la sécurité de la chaîne d’approvisionnement : attendez-vous à davantage d’audits
Outils pour attestation et provenance — des preuves cryptographiques que le code du fournisseur a été produit en toute sécurité
Se concentrer sur sécurité de la chaîne d’approvisionnement logicielle — atténuer les risques liés aux bibliothèques ou modules tiers
Plus d’utilisation de dépôt de code/artefact et environnements de construction fiables
Ces tendances placent la sécurité et l’assurance qualité encore plus au premier plan de l’externalisation.
6. Conclusion et points à retenir
L’ingénierie d’externalisation peut apporter évolutivité et rapidité, mais le contrôle de la qualité et de la sécurité ne doit pas être abandonné. En définissant des normes claires, en sélectionnant rigoureusement les fournisseurs, en intégrant la gouvernance, en intégrant des outils, en appliquant des pratiques sécurisées et en maintenant la transparence, vous pouvez externaliser sans perdre le contrôle.
Alors que l’externalisation continue de se développer à l’échelle mondiale, les clients et les fournisseurs sont confrontés non seulement à des défis techniques et financiers, mais éthique, environnemental et social responsabilités. Les ignorer peut entraîner un risque de réputation, des réactions négatives en matière de réglementation et une perte de confiance des parties prenantes. Dans ce blog, nous approfondirons durabilité, éthique et responsabilité sociale dans le contexte de l’externalisation de logiciels, montrant ce que vous devez prendre en compte et comment le mettre en œuvre.
1. Pourquoi la durabilité et l’éthique sont importantes dans l’externalisation
Voici les principales raisons pour lesquelles ce n’est plus facultatif :
Attentes des parties prenantes: Clients, régulateurs, investisseurs, salariés exigent des opérations durables et éthiques.
Risque de réputation et de marque: Les partenaires d’externalisation associés à des violations du droit du travail, des dommages environnementaux ou une mauvaise utilisation des données peuvent ternir votre marque.
Pression réglementaire: Les lois sur la confidentialité des données, les rapports ESG et les réglementations de la chaîne d’approvisionnement imposent une plus grande surveillance.
Viabilité à long terme: Les pratiques durables réduisent le gaspillage, l’inefficacité, la surutilisation des ressources et améliorent la résilience.
Différenciation: Les entreprises d’externalisation qui intègrent l’éthique et la durabilité peuvent bénéficier d’un positionnement privilégié.
Impératif moral: Au-delà des affaires, les entreprises ont la responsabilité de traiter équitablement les personnes, les communautés et les écosystèmes.
La durabilité et l’éthique du logiciel sont des domaines de recherche en pleine croissance : par exemple, les outils/techniques de génie logiciel durables font l’objet d’un examen critique. En outre, les tendances ESG et technologiques plus larges mettent l’accent sur l’équité, la transparence et la responsabilité dans le déploiement technologique.
Ainsi, intégrer ces valeurs dans l’externalisation est de plus en plus stratégique et non facultatif.
2. Dimensions clés : qu’est-ce que cela signifie en pratique ?
La durabilité, l’éthique et la responsabilité sociale couvrent de multiples dimensions. Voici comment ils se déroulent dans l’externalisation de logiciels :
2.1 Logiciel environnemental/vert
Consommation et efficacité énergétique Le développement et les opérations externalisés consomment du calcul, de l’énergie du centre de données et du refroidissement. Encourager un codage économe en énergie, une architecture à faible consommation et une consommation optimisée des ressources contribue à réduire l’empreinte carbone. Outils, techniques et tendances génie logiciel durable explorez la conception soucieuse de l’énergie, les cadres efficaces, les architectures vertes, etc.
Utilisation efficace des infrastructures Utilisation du sans serveur, de la mise à l’échelle automatique, de la consolidation de la charge de travail, de la planification hors pointe et de l’hébergement écologique.
Cycle de vie et déchets matériels Tenez compte de l’impact environnemental des appareils utilisés, de l’élimination du matériel, des déchets électroniques et de l’approvisionnement de la chaîne d’approvisionnement.
Reporting / compensation carbone Suivez les émissions liées aux opérations externalisées et compensez-les ou atténuez-les.
2.2 Droits du travail et pratiques de travail équitables
Salaires et compensations équitables Veiller à ce que les équipes externalisées soient payées équitablement, avec des horaires, des heures supplémentaires et des avantages raisonnables.
Conditions de travail sécuritaires Garantir que les équipes distantes ou sur site disposent d’environnements de travail sûrs et sains.
Diversité, inclusion et non-discrimination Promouvoir l’équité et l’inclusion entre les sexes, les ethnies et les handicaps.
Liberté d’association / voix collective Respecter le droit des travailleurs de s’organiser, d’exprimer leurs préoccupations et de soulever des griefs.
Éviter le travail abusif/les conditions forcées Pas de « culture de crise » forcée, de pression excessive ou d’exigences contraires à l’éthique.
2.3 Éthique des données, confidentialité et propriété intellectuelle
Confidentialité et consentement S’assurer que les données des clients et des utilisateurs traitées par le fournisseur respectent les lois sur la confidentialité (RGPD, HIPAA, etc.).
Sécurité et protection des données Chiffrement, contrôle d’accès, journalisation d’audit, gestion sécurisée des secrets.
Gestion de la propriété intellectuelle (PI) Des contrats clairs sur la propriété, les licences, les droits, la réutilisation et les œuvres dérivées.
Biais, équité et éthique algorithmique Si le fournisseur crée de l’IA/ML, assurez-vous qu’il se prémunit contre les préjugés, l’équité et les utilisations abusives. Les compromis des systèmes d’IA incluent des coûts environnementaux, sociaux et éthiques qui doivent être transparents et pris en compte. arXiv
2.4 Gouvernance, transparence et responsabilité
Transparence dans les opérations Visibilité sur les décisions des fournisseurs, les processus, les flux de données, les sous-traitants et les chaînes d’approvisionnement.
Cadres de responsabilisation Qui est responsable des échecs, des manquements, des manquements éthiques.
Audits, vérification par des tiers et certification Par exemple, durabilité ISO, audits, reporting ESG, normes de transparence.
Rapports et mesures des parties prenantes Publier des KPI de développement durable, des indicateurs éthiques, des rapports d’impact aux partenaires ou au public.
2.5 Impact communautaire et social
Engagement de la communauté locale Les opérations externalisées sont souvent situées dans les communautés : quelle est la contribution du fournisseur au niveau local (compétences, emplois, infrastructure) ?
Formation, transfert de compétences et renforcement des capacités locales Assurez-vous que votre sous-traitance contribue au développement local, et pas seulement à l’extraction.
Éviter les externalités négatives S’assurer que les opérations des fournisseurs n’aggravent pas les inégalités, les dommages environnementaux ou les dommages sociaux.
3. Risques, compromis et tensions
Intégrer la durabilité et l’éthique dans l’externalisation ne se fait pas sans friction. Certaines des tensions comprennent :
Compromis entre coût et impact Les pratiques vertes, les salaires équitables, les audits et les certifications coûtent plus cher. Vous devez équilibrer le coût et l’impact éthique.
Chaînes d’approvisionnement complexes et sous-traitance Les fournisseurs font souvent appel à des sous-traitants ou à plusieurs niveaux : il est difficile de contrôler l’éthique entre eux.
Greenwashing / engagements superficiels Les allégations de « durabilité » peuvent être superficielles à moins qu’elles ne soient étayées par des pratiques mesurables.
Jeux métriques/fausses déclarations Sans une surveillance rigoureuse, les indicateurs de durabilité peuvent être manipulés.
Des objectifs contradictoires Vitesse, coût, qualité ou durabilité : les compromis doivent être gérés.
Risque éthique des données/IA Les solutions d’IA des fournisseurs peuvent intégrer des préjugés ou causer des dommages sociaux à moins d’être auditées de manière approfondie.
Inadéquation des réglementations selon les zones géographiques L’emplacement du fournisseur peut avoir des normes, des lois ou des applications différentes.
Défis de mesure Quantifier l’impact environnemental/social peut s’avérer non trivial, notamment en ce qui concerne l’empreinte logicielle.
La littérature universitaire sur l’intégration de la durabilité dans l’IA prévient que si l’IA apporte des avantages, elle introduit également des compromis environnementaux et sociaux qui nécessitent une évaluation holistique.
4. Cadres, normes et analyse comparative
Pour intégrer l’éthique et la durabilité de manière fiable, l’alignement sur les normes et les cadres permet de :
Génie logiciel durable (ESS) / Principes du logiciel vert Intégrer la sensibilisation à l’énergie, l’efficacité et l’éco-conception tout au long du cycle de vie des logiciels.
Cadres ESG et RSE Normes de reporting environnemental, social et de gouvernance ; indices de durabilité; Reporting RSE.
Certifications et audits ISO 14001 (environnement), ISO 26000 (responsabilité sociale), SA8000, B Corp, etc.
Cartes de pointage de durabilité des fournisseurs Critères internes que vous définissez (par exemple, utilisation du carbone, pratiques de travail, audits) et notez les fournisseurs potentiels.
Vérification par des tiers / audits éthiques Audits indépendants pour valider les réclamations des fournisseurs.
Divulgations transparentes sur la chaîne d’approvisionnement Exigez une cartographie des fournisseurs des sous-traitants et des mesures d’impact.
Analyses de cycle de vie (ACV) Pour les logiciels + matériels, évaluation du carbone, de l’utilisation des ressources par module, dans le cadre des décisions d’architecture.
L’utilisation de cadres permet de passer des promesses à des actions mesurables et fiables.
5. Meilleures pratiques et étapes réalisables
Voici une feuille de route d’actions concrètes que vous (en tant que client ou responsable d’externalisation) pouvez entreprendre :
Définissez dès le départ vos objectifs en matière de développement durable et d’éthique Qu’est-ce qui compte le plus : le carbone, le travail, l’équité sociale, l’éthique des données ? Rendez-les explicites dans votre demande de propositions ou votre contrat.
Intégrer des clauses éthiques et durables dans les contrats Inclure des normes minimales, des audits, des droits aux inspections et des sanctions en cas de violation.
Fournisseurs vétérinaires sur la maturité en matière d’éthique et de durabilité Demandez des politiques, des audits, des antécédents et des mesures. Préférez les fournisseurs qui ont déjà des engagements.
Exiger la transparence et le reporting des fournisseurs Rapports mensuels ou trimestriels sur la consommation d’énergie, le carbone, les mesures de main-d’œuvre et l’impact social.
Demander des audits et des certifications en matière de développement durable/éthique Audits indépendants, validation par des tiers, certifications si possible.
Construire des points de contrôle de durabilité lors de la livraison Aux jalons, vérifiez l’efficacité énergétique de l’architecture, l’équité des algorithmes, utilisez un code efficace.
Encourager le renforcement des capacités partagées Formation des fournisseurs, comités conjoints d’examen éthique, renforcement des compétences locales.
Utiliser les mesures et les KPI Suivez des mesures telles que l’intensité carbone des fournisseurs par module, le nombre de résultats d’audit, la diversité et les statistiques de main-d’œuvre.
Soyez prêt à payer plus pour une prime éthique Reconnaissez que les fournisseurs véritablement durables/éthiques peuvent coûter plus cher – budgétisez en conséquence.
Plan d’évolution et d’amélioration continue La durabilité est un voyage. Réévaluer, itérer, améliorer les normes d’année en année.
Ces étapes vous permettent d’intégrer la responsabilité dans l’externalisation, sans la considérer après coup.
6. Exemples de cas et tendances émergentes
Voici des exemples ou des tendances indiquant une dynamique :
Recherche en Outils, techniques et tendances en matière d’ingénierie logicielle durable explique comment l’industrie du logiciel prend de plus en plus en compte l’énergie, l’utilisation des ressources et la conception durable dans la pratique.
La théorie de la durabilité des logiciels évolue : le génie logiciel durable est « stratifié » et multisystémique, ce qui signifie que la durabilité doit aborder plusieurs niveaux (techniques, organisationnels, environnementaux).
Dans le domaine des services financiers, une étude de cas récente montre des différences de perception entre la direction (qui se concentre sur la durabilité technique/économique) et les développeurs (qui valorisent la durabilité des ressources humaines et de la charge de travail), ce qui indique que les dimensions éthiques et sociales sont aussi importantes que les dimensions environnementales.
Sur la frontière ESG/technologie, la pression s’accentue en faveur de la transparence et de l’équité dans le domaine technologique. Les tendances 2025 de McKinsey soulignent que innovation responsable et la responsabilité seront des différenciateurs clés.
Bien que les études de cas publiques spécifiques sur la « durabilité de l’externalisation » soient plus rares, ces tendances soulignent que la durabilité des logiciels devient courante – l’externalisation ne doit pas être à la traîne.
7. Le chemin à parcourir : ce qu’il faut surveiller
Normalisation et réglementation: Les lois ESG et développement durable couvriront de plus en plus les technologies et les chaînes d’approvisionnement.
Demande des clients / appels d’offres: De plus en plus de clients exigeront des fournisseurs des références en matière d’éthique et de durabilité.
Examen des compromis entre l’IA et la durabilité: Étant donné que les logiciels basés sur l’IA consomment beaucoup d’énergie, les tests d’équilibre entre capacité et coût environnemental vont s’intensifier.
Responsabilité de la chaîne d’approvisionnement: Les fournisseurs seront tenus responsables de l’éthique, de l’impact environnemental et des pratiques de travail de leurs sous-traitants.
Meilleures mesures et outils: Des outils pour mesurer la consommation d’énergie, l’empreinte et l’équité des logiciels – plus de maturité viendra.
Rapports publics et transparence: Les fournisseurs publieront de plus en plus de mesures de durabilité, d’audits tiers et de rapports d’impact éthique.
Pression des consommateurs et des employés: Les talents et les utilisateurs peuvent privilégier les entreprises qui externalisent de manière éthique et durable.
Garder une longueur d’avance permet de garantir la pérennité de votre stratégie d’externalisation.
8. Conclusion et listes de contrôle stratégiques
Intégration durabilité, éthique et responsabilité sociale L’externalisation des logiciels n’est plus une option : c’est un impératif stratégique. Bien le faire renforce la confiance, la résilience et l’avantage concurrentiel.
Points clés à retenir :
Utiliser durabilité dans l’externalisation des logiciels comme mot-clé de guidage dans les titres, le contenu et les liens.
Tenez compte des dimensions environnementales, sociales et éthiques, et pas seulement des dimensions techniques ou financières.
Utilisez les contrats, les audits, la transparence et les mesures pour faire respecter la responsabilité.
Préférez les fournisseurs ayant une maturité, des politiques et une volonté d’être évalués éprouvées.
Considérez la durabilité comme un voyage continu et non comme une case à cocher.
Les microservices offrent de grandes promesses : modularité, évolutivité et déploiements indépendants. Mais de nombreuses équipes tombent dans des pièges qui transforment leurs « victoires en matière de microservices » en souffrance. Voici cinq erreurs courantes commises par les développeurs – et comment éviter.
1. Erreur n°1 : limites de service médiocres et « mauvaise granularité »
Ce qui se produit
Les développeurs créent parfois des microservices de manière trop fine ou trop grossière :
Des services qui ne font guère plus que CRUD pour une seule entité – si nombreux que les changements nécessitent de toucher plusieurs services.
Ou des services trop « gros », porteurs de trop de responsabilités et redevenant monolithiques.
Les dépendances s’enchevêtrent et la coordination entre services devient lourde.
Il s’agit d’un anti-modèle connu : limites de service inappropriées.
Pourquoi c’est un problème
Augmente le couplage : les changements se répercutent sur tous les services.
Réduit la déployabilité et l’autonomie indépendantes.
Rend le débogage, la gestion des versions et la coordination plus difficiles.
Comment l’éviter
Utiliser Conception pilotée par domaine (DDD) et contextes délimités pour définir les limites des services.
Utilisez les capacités métier plutôt que les couches techniques comme ligne de démarcation.
Commencez par des services plus grossiers, puis refactorisez-les progressivement en fonction des besoins.
Couplage de moniteur : si deux services changent souvent ensemble, reconsidérez la fusion ou la refonte.
2. Erreur n°2 : base de données partagée/couplage de données
Ce qui se produit
Les développeurs autorisent parfois plusieurs services à lire/écrire les mêmes tables ou schéma de base de données. Ou le service A interroge directement les tables appartenant au service B.
Cela brise le principe de autonomie des services et conduit à un couplage serré.
Pourquoi c’est un problème
Viole l’encapsulation : fuites de données internes aux services.
Les modifications apportées au schéma d’un service en interrompent les autres.
Rend la migration, la mise à l’échelle ou les mises à niveau indépendantes presque impossibles.
Comment l’éviter
Chaque microservice doit posséder ses propres données (base de données ou schéma) et exposer des API pour y accéder.
Utilisez la synchronisation basée sur les événements (publication/abonnement) ou les modèles de réplication de données si d’autres services ont besoin de données dérivées.
Utilisez des caches ou des flux de données asynchrones plutôt que le couplage direct.
3. Erreur n°3 : créer un « monolithe distribué »
Ce qui se produit
Sous couvert de microservices, un système finit par être un réseau étroitement couplé : les services dépendent trop les uns des autres et les déploiements doivent être coordonnés entre de nombreux services.
C’est ce qu’on appelle souvent un monolithe distribué.
Pourquoi c’est un problème
Vous perdez de nombreux avantages des microservices : déployabilité indépendante, isolation des pannes, mise à l’échelle.
Une panne dans un service se répercute en cascade.
La coordination des sorties redevient douloureuse.
Comment l’éviter
Assurer accouplement lâche entre services (communication asynchrone, files d’attente de messages, architecture événementielle).
Utiliser disjoncteurs, délais d’attente, stratégies de repli pour éviter des pannes en cascade. (le disjoncteur est un modèle courant dans les systèmes distribués)
Concevoir des API/contrats intentionnellement plutôt que des couplages ad hoc.
4. Erreur n°4 : négliger l’observabilité, la surveillance et la journalisation
Ce qui se produit
Les équipes créent de nombreux petits services sans instrumentation décente : journalisation, traçage et métriques limités. Ils surveillent uniquement chaque service de manière isolée, mais pas leur fonctionnement de bout en bout.
L’une des erreurs « ne pas omettre l’observabilité » répertoriées dans les leçons sur les microservices de Thoughtworks.
Pourquoi c’est un problème
Lorsqu’un problème échoue, il est difficile d’en retracer les causes profondes dans tous les services.
Le débogage des systèmes distribués sans visibilité des traces est extrêmement pénible.
Vous perdez la visibilité sur les performances, la latence, la propagation des erreurs et les goulots d’étranglement.
Comment l’éviter
Mettre en œuvre traçage distribué (par exemple OpenTelemetry, Jaeger), demandez des identifiants lors des appels d’API.
Collectez des métriques (latence, taux d’erreur, débit) par service et par agrégat.
Utilisez la journalisation structurée, les ID de corrélation et la propagation du contexte.
Définissez des SLA/alertes pour la dégradation des performances interservices, et pas seulement des métriques pour un seul service.
Des études empiriques montrent que la complexité des microservices augmente les difficultés de surveillance, de test et de conception.
5. Erreur n°5 : tests, CI/CD et gestion des contrats inadéquats
Ce qui se produit
Les développeurs traitent les tests comme des monolithes : des tests lourds de bout en bout, peu ou pas du tout. tests contractuelspas de pipelines d’automatisation pour chaque service.
Ils ignorent également ou appliquent faiblement la gestion des versions des contrats API entre les services.
Pourquoi c’est un problème
Les nouvelles versions brisent les consommateurs en aval.
Les API peuvent changer de manière incompatible, provoquant des échecs d’exécution.
Les déploiements deviennent risqués et manuels.
Comment l’éviter
Mettre en œuvre tests sous contrat (contrats axés sur le consommateur) afin que les consommateurs et les fournisseurs de services s’accordent sur le comportement de l’API.
Automatisez les pipelines CI/CD par microservice : créez, testez et déployez de manière indépendante.
Utilisez des stratégies de gestion des versions et de compatibilité descendante pour les API.
Incorporez des tests unitaires, d’intégration, de bout en bout et de bout en bout au-delà des limites des services.
Utilisez l’isolation des données de test et testez les doubles/stubs pour les services dépendants.
6. Erreurs bonus et thèmes généraux
Voici quelques pièges supplémentaires qui méritent d’être surveillés :
Adopter les microservices trop tôt — les organisations interviennent avant d’être prêtes (automatisations, culture, structure d’équipe).
Normes incohérentes/fragmentation technologique — trop de frameworks, styles d’API incohérents, manque de gouvernance uniforme.
Ignorer la dette technique et reporter la refactorisation — les systèmes de microservices accumulent des dettes ; le manque de nettoyage continu fait mal à long terme.
Dépendance excessive à l’égard de la communication synchrone — les appels synchrones entre microservices introduisent de la latence et du couplage. Mieux vaut privilégier les conceptions asynchrones ou événementielles.
7. Rassembler tout cela : votre plan d’action
Erreur
Principales mesures d’atténuation/meilleures pratiques
Mauvaises limites de service
Utiliser DDD, démarrer grossièrement, refactoriser, surveiller le couplage
Bases de données partagées
Chaque service est propriétaire de ses données, utilise des événements ou des API pour les données interservices
Monolithe distribué
Couplage lâche, modèles tels que disjoncteur, repli, API asynchrones
Faible observabilité
Implémenter des traces, des métriques, une journalisation structurée et des tableaux de bord interservices
Tests/contrats inadéquats
Utiliser des tests contractuels axés sur le consommateur, des pipelines CI/CD, des versions et des tests automatisés
Étapes à suivre pour les adopter dans votre prochain projet :
Commencez par une modélisation de domaine claire et des contextes délimités.
Définir les contrats API avant la mise en œuvre.
Configurez des pipelines automatisés et appliquez des tests contractuels le plus tôt possible.
Services d’instruments dès le premier jour (traçage, métriques, journalisation).
Surveillez le couplage et les dépendances de service, refactorisez si nécessaire.
Utilisez des modèles de résilience (délai d’attente, disjoncteur, nouvelle tentative, repli).
Examiner et faire évoluer les normes, la gouvernance et les pratiques en permanence.
Conclusion et points à retenir
La création de microservices est puissante, mais seulement si elle est exécutée avec discipline. De nombreux développeurs tombent sur des pièges courants : mauvaises limites, couplage de données, monolithes distribués, manque d’observabilité et tests/contrats faibles.
En reconnaissant ces erreurs à l’avance, en appliquant une conception axée sur le domaine, en appliquant les contrats, en instrumentant correctement et en automatisant rigoureusement, vous donnez à votre architecture de microservices une plus grande chance de tenir ses promesses.
Dans le paysage technologique actuel en évolution rapide, le cloud natif est plus qu’un mot à la mode : c’est un changement fondamental. Les applications créées de manière native dans le cloud peuvent évoluer, évoluer, récupérer et fournir des fonctionnalités plus rapidement que jamais. Mais que gagne-t-on exactement à adopter ce paradigme ? Ci-dessous sont 10 avantages convaincants (étayés par des exemples et des sources d’experts) qui font du cloud natif une voie incontournable en 2025 et au-delà.
1. Que signifie « Cloud natif » ?
Avant d’énumérer les avantages, définissons une définition de base. Les applications cloud natives sont conçues pour exploiter pleinement l’infrastructure cloudemployant des modèles tels que des microservices, des conteneurs, une orchestration (par exemple Kubernetes), une infrastructure immuable et des API déclaratives.
Ils sont conçus pour être résilients, évolutifs, modulaires et fonctionner dans des environnements cloud dynamiques et distribués.
Dans cet esprit, voici les principaux avantages.
2. Avantage n°1 : évolutivité et élasticité
L’un des avantages les plus importants est la capacité d’évoluer de manière dynamique – à la hausse ou à la baisse – en fonction de la demande.
Les applications cloud natives peuvent lancer automatiquement des instances ou des services supplémentaires lors des pics de trafic et les réduire pendant les périodes d’inactivité.
Cette élasticité évite le surprovisionnement « juste au cas où », réduisant ainsi le gaspillage et garantissant les performances.
Des recherches récentes (par ex. Libérer une véritable élasticité pour l’ère du cloud natif avec Dandelion) vise à pousser plus loin l’élasticité, en réduisant les frais généraux de démarrage à froid et le gaspillage de ressources.
3. Avantage n°2 : résilience et tolérance aux pannes
Les architectures cloud natives sont conçues en pensant à l’échec :
Les composants sont découplés (microservices), donc la défaillance d’un service ne fait pas nécessairement tomber l’ensemble du système.
Des outils tels que Kubernetes permettent des vérifications de l’état, l’auto-réparation (redémarrage des pods défaillants) et le basculement automatique.
Une meilleure isolation des défauts, une dégradation progressive et des modèles de disjoncteurs deviennent plus faciles à mettre en œuvre.
Cela augmente la disponibilité et la confiance dans les systèmes de production.
4. Avantage n°3 : délai de mise sur le marché/vitesse plus rapide
Le cloud natif permet une rapidité dans laquelle les applications existantes ont du mal à :
Les services peuvent être développés, testés et déployés indépendamment, permettant ainsi un travail parallèle des équipes.
L’automatisation, le CI/CD et la conteneurisation réduisent les frais généraux manuels et libèrent les frictions.
Vous pouvez itérer plus rapidement et répondre aux changements du marché, aux demandes de fonctionnalités ou aux corrections de bugs avec plus de rapidité que dans les systèmes monolithiques.
En bref : vitesse + sécurité.
5. Avantage n°4 : rentabilité et utilisation optimisée des ressources
Le cloud natif peut réduire à la fois les coûts d’investissement et d’exploitation :
Modèle de paiement à l’utilisation : vous payez uniquement pour les ressources utilisées.
Le partage des ressources et la multilocation permettent d’utiliser l’infrastructure plus efficacement.
Réduire les coûts pendant les heures creuses permet de réaliser des économies.
Réduction des frais opérationnels (moins d’opérations manuelles, moins de grandes mises à niveau monolithiques).
Ainsi, le cloud natif conduit souvent à un meilleur retour sur investissement.
6. Avantage n°5 : portabilité et évitement du verrouillage du fournisseur
L’une des critiques formulées à l’encontre de l’orientation vers le cloud est la dépendance vis-à-vis du fournisseur, mais les modèles cloud natifs contribuent à atténuer ce phénomène :
Lorsqu’elle est créée à l’aide de conteneurs, de microservices et d’abstractions, l’application devient portable entre les fournisseurs de cloud.
Le découplage des dépendances de service des API cloud spécifiques permet de migrer plus facilement des stratégies multi-cloud.
Cela donne une flexibilité stratégique et un pouvoir de négociation.
7. Avantage n°6 : automatisation, DevOps et livraison continue
Le cloud natif est étroitement associé aux pratiques de développement modernes :
Infrastructure as Code (IaC), provisionnement automatisé, configurations déclaratives.
Les pipelines d’intégration et de livraison continues deviennent plus fluides grâce à la cohérence des conteneurs.
Les tests, déploiements, restaurations et versions automatisés peuvent être intégrés aux services.
Le résultat : moins de travail, moins d’erreurs manuelles, des versions plus prévisibles.
Cet avantage accélère l’ensemble du cycle de vie du logiciel.
8. Avantage n°7 : meilleure observabilité et surveillance
Les services étant modulaires, le cloud natif facilite l’instrumentation, la surveillance, le traçage et l’observation :
Vous pouvez suivre les métriques par service (latence, taux d’erreur).
Le traçage distribué entre les microservices facilite l’analyse des causes profondes.
Agrégation de journaux, métriques, tableaux de bord, alertes avec une granularité fine.
Cette visibilité conduit à une meilleure fiabilité et à des réparations plus rapides.
9. Avantage n°8 : amélioration de la sécurité et de la conformité
Même si le cloud natif introduit une certaine complexité en matière de sécurité, il contribue également à la sécurité s’il est bien fait :
Les plates-formes cloud fournissent souvent des contrôles de sécurité intégrés, une gestion des identités et des accès, un cryptage et une application des politiques.
Vous pouvez isoler les services, réduire le rayon d’explosion et les composants du bac à sable.
Les correctifs, mises à jour et mises à niveau peuvent être déployés rapidement et automatiquement.
La conformité est plus facile car le contrôle de l’infrastructure est plus standardisé et vérifiable.
10. Avantage n°9 : Innovation et flexibilité pour la croissance des écosystèmes
Le cloud natif soutient l’innovation et la croissance future :
Vous pouvez expérimenter de nouveaux services (par exemple IA, sans serveur, pilotés par événements), mélanger et assortir des composants.
L’architecture des microservices vous permet de remplacer ou de mettre à niveau des pièces individuelles sans affecter l’ensemble.
Les équipes peuvent adopter de nouvelles piles, langages et frameworks par service sans grandes répercussions.
L’écosystème de services cloud (bases de données, ML, streaming) peut être intégré plus facilement.
11. Avantage n°10 : Efficacité énergétique et architecture durable
Il s’agit d’un avantage plus avancé mais croissant :
Les systèmes cloud natifs peuvent optimiser plus finement l’utilisation des ressources, en désactivant les services inactifs, en effectuant une mise à l’échelle précise et en réduisant le gaspillage de calcul.
Des recherches récentes introduisent des cadres permettant de mesurer la consommation d’énergie à toutes les couches des systèmes cloud natifs et de faire des compromis entre la consommation d’énergie et les performances.
Plus votre architecture est bonne, plus l’empreinte carbone est faible à travaux équivalents.
Le cloud natif n’est donc pas seulement meilleur d’un point de vue technique, il contribue également à la durabilité.
12. Défis et compromis dont il faut être conscient
Soyez honnête : le cloud natif est puissant, mais il n’est pas exempt de compromis :
Complexité : la gestion des systèmes distribués, des microservices, de l’orchestration est plus complexe.
Frais généraux opérationnels : plus de composants à surveiller, sécuriser, maintenir.
Courbe d’apprentissage et changement culturel : les équipes doivent adopter le DevOps, l’ingénierie de fiabilité et de nouvelles pratiques.
Démarrages à froid, latence de démarrage (surtout en serverless).
Surcharge et latence des communications interservices.
Sur-ingénierie d’applications plus petites – pour des cas d’utilisation triviaux, les monolithes peuvent encore suffire.
Les connaître vous aide à planifier judicieusement.
13. Comment commencer (étapes pratiques)
Voici un chemin simple pour adopter le cloud natif :
Commencez par un service pilote – choisissez un domaine non critique et créez-le en tant que cloud natif.
Conteneuriser et orchestrer — utilisez Docker + Kubernetes (ou similaire) pour l’orchestration.
Adopter les pratiques DevOps — automatiser le CI/CD, le provisionnement de l’infrastructure.
Refactoriser progressivement les composants existants — migre progressivement les pièces.
Surveiller les coûts et les performances – Adaptez l’utilisation des ressources et le comportement du service.
Formez votre équipe et votre culture — investir dans la connaissance des systèmes distribués et des modèles de défaillance.
Réviser, itérer et évoluer — le cloud natif ne se fait pas « une fois » mais évolue.
14. Conclusion et points à retenir
Adopter applications cloud natives débloque des avantages stratégiques réels : évolutivité, résilience, rapidité, rentabilité, portabilité, innovation et même durabilité. Mais cela nécessite des investissements, de la discipline et une architecture soignée.
Points clés à retenir
Utiliser avantages des applications cloud natives comme mot-clé principal dans le titre, la méta et le contenu.
Les 10 principaux avantages ci-dessus justifient la migration ou l’investissement dans le cloud natif.
Soyez conscient des défis et prévoyez de les atténuer.
Commencez petit, construisez progressivement et faites évoluer le reste de votre système.
Alors que les systèmes de santé exploitent de plus en plus le Big Data (DSE, dossiers cliniques, génomique, flux de capteurs), les enjeux réglementaires augmentent. Se conformer aux règles de confidentialité, de sécurité, de gouvernance des données, de surveillance de l’IA et d’interopérabilité est complexe. Si vous vous trompez, les conséquences sont lourdes : amendes, responsabilité juridique, préjudice aux patients, atteinte à la réputation. Explorons les principaux défis et comment les surmonter.
1. Pourquoi le Big Data dans le domaine de la santé est hautement réglementé
Avant de se lancer dans les défis, il est utile de voir pourquoi le big data dans le domaine de la santé attire tellement l’attention des régulateurs :
Les données traitées dans le domaine de la santé sont intrinsèquement sensible (antécédents médicaux, diagnostics, données biométriques, données génétiques).
Les décisions fondées sur des données peuvent avoir un impact sur les soins, les droits et les résultats des patients ; les erreurs ou les préjugés peuvent causer de réels préjudices.
Les systèmes de santé traversent souvent les frontières institutionnelles, régionales et nationales, ce qui rend la réglementation très complexe.
Les systèmes d’IA font l’objet d’une surveillance croissante, en particulier dans la prise de décision clinique ou réglementaire.
Le partage des données, l’interopérabilité et l’utilisation secondaire (recherche, santé publique) créent des tensions avec le droit à la vie privée.
Pour cette raison, les réglementations imposent des obligations strictes sur la manière dont les données sont collectées, stockées, partagées, traitées, auditées et éliminées.
2. Principaux défis en matière de réglementation et de conformité
Voici les principaux défis en matière de réglementation et de conformité lors de l’application du Big Data dans le secteur de la santé :
2.1 Lois sur la confidentialité et la protection des données (HIPAA, RGPD, etc.)
Aux États-Unis, HIPAA (Loi sur la portabilité et la responsabilité de l’assurance maladie) régit les informations de santé protégées (PHI) : comment elles doivent être protégées, quand elles peuvent être utilisées, les droits des patients, la notification des violations.
En vertu du RGPD (UE), les données de santé constituent une « catégorie spéciale » nécessitant des garanties supplémentaires et un consentement plus strict, une limitation des finalités et une minimisation des données.
Différences dans les lois nationales ou étatiques sur la protection de la vie privée.
Veiller à ce que l’anonymisation/désidentification respecte les seuils légaux (et résister au risque de réidentification).
Les définitions juridiques, l’application et les sanctions évoluent.
Un article de 2024 note que les modifications proposées à la HIPAA renforceront les exigences en matière de chiffrement, d’authentification multifactorielle, de réponse aux incidents et d’application. En outre, une étude sur la confidentialité des données dans le domaine des soins de santé met en évidence les définitions incohérentes, le manque de protocoles standardisés et les divergences sémantiques comme obstacles.
2.2 Gouvernance des données, consentement et droits des patients
Obtention consentement éclairé pour la collecte, l’utilisation et la réutilisation secondaire des données (par exemple, recherche).
Gestion des demandes de révocation de consentement et de suppression de données.
Garantir que les patients peuvent accéder, corriger ou supprimer leurs données.
Application de la limitation des finalités (données utilisées uniquement à des fins spécifiées).
Assurer la provenance et le lignage des données (comment les données sont nées, transformations).
2.3 Interopérabilité, normes et partage de données
Les prestataires de soins utilisent des systèmes diversifiés (DSE, systèmes de laboratoire, imagerie), avec des formats et une sémantique hétérogènes.
L’absence d’adoption universelle des normes (HL7, FHIR, LOINC, SNOMED) rend difficile la combinaison significative des données.
Les régimes réglementaires imposent parfois l’interopérabilité ou les « API ouvertes », créant ainsi des tensions avec la confidentialité ou la logique commerciale.
La normalisation peut contribuer à garantir la conformité et l’auditabilité.
2.4 IA / Responsabilité algorithmique et explicabilité
Quand le Big Data pilote les modèles d’IA/ML utilisés pour le diagnostic, l’évaluation des risques, les suggestions de traitement, les régulateurs l’exigent explicabilitééquité, évitement des préjugés, responsabilité.
Les modèles doivent souvent répondre aux normes réglementaires en matière de sécurité, de robustesse et d’auditabilité.
L’ambiguïté réglementaire demeure quant à la manière dont « l’IA dans les soins de santé » est réglementée : les organismes de contrôle évoluent.
Les enquêtes de recherche indiquent qu’un apprentissage automatique responsable et conforme en médecine doit s’aligner sur la confidentialité, la transparence, la sécurité, l’équité et la non-discrimination.
2.5 Conformité transfrontalière/juridictionnelle
Les flux de données transfrontaliers soulèvent des problèmes : un ensemble de données stocké ou traité dans une autre juridiction peut être soumis à ses lois (par exemple, le RGPD).
Exigences de localisation, de résidence des données, restrictions de transfert transfrontalier.
Concilier plusieurs régimes juridiques dans une analyse ou une recherche multinationale.
2.6 Rapports sur la sécurité, les risques de violation et les incidents
Les soins de santé sont une cible privilégiée des cyberattaques et des ransomwares.
Mandat réglementaire rapport d’incidentdélais de notification des violations, sanctions.
Assurer le chiffrement en transit, au repos ; contrôles d’accès stricts ; audits de sécurité réguliers.
L’article « Risques et conformité en matière de soins de santé : 5 défis clés » souligne que la complexité réglementaire, les risques liés aux tiers et les cybermenaces augmentent.
2.7 Auditabilité, provenance et traçabilité
Les régulateurs attendent de vous que vous présentiez une piste d’audit de l’accès aux données, des étapes de traitement, des transformations et des décisions de modèle.
La gestion des versions, la journalisation et les enregistrements immuables sont essentiels.
Les outils doivent prouver la chaîne de conservation des données et des résultats.
2.8 Risque et conformité des fournisseurs/tiers
Les systèmes Big Data s’appuient souvent sur des fournisseurs (cloud, analyses, plateformes d’IA).
S’assurer que les fournisseurs se conforment aux mêmes réglementations, disposent de contrats appropriés et de contrôles d’accès aux données.
Responsabilité, surveillance, audits de tiers.
3. Exemples réels et tendances de la pression réglementaire
L’administration Biden propose des règles de cybersécurité plus strictes pour les soins de santé, notamment des mises à jour de la règle de sécurité HIPAA avec le cryptage requis, l’authentification multifactorielle et des contrôles de conformité forcés.
Les praticiens du droit de la vie privée identifient six défis émergents en matière de confidentialité des données dans le secteur des soins de santé : les décisions sur les données des patients, l’utilisation de l’IA, les mises à jour réglementaires mondiales, les tendances en matière de litiges, l’utilisation de technologies de suivi et l’expansion de la confidentialité au niveau des États.
Dans le domaine académique, des enquêtes sur ML responsable et conforme à la réglementation pour la médecine illustrent l’écart entre l’innovation en IA et l’alignement réglementaire.
Dans les articles analysant le Big Data dans le domaine de la santé, la confidentialité et la sécurité des données figurent parmi les obstacles les plus cités.
Ces pressions réelles montrent que la conformité réglementaire n’est pas hypothétique : elle est immédiate et évolutive.
4. Stratégies d’atténuation et meilleures pratiques
Comment les organismes de santé et les équipes techniques peuvent-ils créer des systèmes Big Data conformes et minimisant les risques ?
Meilleures pratiques
Confidentialité dès la conception et minimisation des données Créez des systèmes qui collectent uniquement les données nécessaires, anonymisent ou regroupent lorsque cela est possible, par défaut la confidentialité.
Gestion du consentement fort Utilisez des cadres de consentement dynamiques et précis. Suivez et appliquez le consentement pour les utilisations secondaires.
Modèles de données standard et cadres d’interopérabilité Utilisez FHIR, HL7, OMOP, CDISC le cas échéant pour garantir la sémantique des données et faciliter l’auditabilité. (Par exemple, CDISC est utilisé dans la recherche clinique réglementaire.)
Contrôles d’accès et sécurité basée sur les rôles Moindre privilège strict, séparation des tâches, authentification multifacteur.
Cryptage et transmission sécurisée Chiffrez toujours les données en transit et au repos ; utiliser une gestion sécurisée des clés, des HSM, etc.
Audit et journalisation Conservez des journaux immuables sur l’accès aux données, les étapes de traitement, les transformations et les décisions de modèle.
Gouvernance et explicabilité du modèle Pour les systèmes ML/AI, conservez l’interprétabilité du modèle, la gestion des versions, la détection des biais et l’évaluation de l’impact.
Conformité des fournisseurs et des tiers Exiger des obligations contractuelles, des audits, des certifications de conformité, des évaluations des fournisseurs.
Surveillance continue et évaluation des risques Effectuez régulièrement des audits de conformité, des tests d’intrusion et des évaluations de l’impact sur la vie privée.
Stratégie de conformité entre juridictions Cartographiez les lois dans tous les pays, définissez des politiques de résidence des données, concevez des flux de données licites (par exemple, des clauses contractuelles standard).
Organes de gouvernance et de surveillance Mettre en place des comités de conformité internes, nommer un délégué à la protection des données (DPO), des comités d’éthique.
Transparence et droits des patients Fournir aux personnes concernées l’accès, les corrections, la suppression et des avis de confidentialité clairs.
En combinant ces pratiques, vous réduisez considérablement le risque réglementaire.
5. Feuille de route réglementaire : à quoi s’attendre dans les années à venir
Voici ce à quoi les organisations de Big Data et de soins de santé devraient prêter attention :
Évolution des propositions de modernisation de la HIPAA (comme mentionné ci-dessus) pour imposer des contrôles techniques plus stricts.
Plus de réglementation sur l’IA : exiger des audits, des explications, la sécurité, l’atténuation des préjugés, l’alignement sur l’éthique.
Application et sanctions plus strictes en cas de violation de données dans le secteur de la santé.
Régimes mondiaux de protection de la vie privée convergents ou contradictoires (règles transfrontalières en matière de données).
Mandats d’interopérabilité (droit des patients aux données, accès API).
Demande accrue d’auditabilité, de provenance, de traçabilité des données dans les preuves du monde réel et les soumissions réglementaires.
Utilisation de technologies émergentes pour la conformité : contrats intelligents blockchain pour faire respecter la politique de données. (Par exemple, un article propose une blockchain + des contrats intelligents pour appliquer les politiques d’accès au DSE.)
Exigences croissantes en matière d’« IA explicable », en particulier dans les systèmes de décision clinique.
Être proactif vous aide à ne pas être réactif.
6. Conclusion et points à retenir
Le défis réglementaires et de conformité du Big Data dans le secteur de la santé sont complexes, multidimensionnels et en constante évolution. Mais ils ne sont pas insurmontables : grâce à une conception, une gouvernance et une vigilance réfléchies, vous pouvez exploiter le Big Data de manière responsable sans enfreindre les lois.
💡 Résumé des points clés
Utiliser conformité big data soins de santé comme mot-clé d’ancrage dans le contenu.
Domaines de défis majeurs : loi sur la protection de la vie privée (HIPAA, RGPD), consentement, interopérabilité, responsabilité de l’IA, sécurité, auditabilité, risque fournisseur.
Les tendances réglementaires du monde réel imposent désormais des mandats techniques plus stricts.
Meilleures pratiques : confidentialité dès la conception, gestion du consentement, adoption de normes, chiffrement, journalisation, gouvernance des modèles, conformité des fournisseurs.
Attendez-vous à une réglementation plus stricte à l’avenir – planifiez à l’avance.
Python est un langage de programmation puissant. Il est assez facile à prendre en main et possède une forte communauté dans le monde entier. C’est pourquoi il dispose d’un vaste ensemble de bibliothèques générées et maintenues par les utilisateurs pour toutes sortes de choses.
Aujourd’hui, nous allons discuter exclusivement des bibliothèques Python dans le traitement d’images, un sujet tous les jours. Développeur Python devrait être familier avec. Le traitement d’images a de nombreuses utilisations dans le monde réel : par exemple, l’OCR, la conception et la médecine légale l’utilisent tous dans une certaine mesure.
Que vos tâches de traitement d’image impliquent l’amélioration de la qualité de l’image, la détection d’objets ou l’automatisation de tâches visuelles, l’écosystème Python fournit une bibliothèque pour le faire. Alors, vérifions-les.
Importance du traitement des images
Le traitement d’images fait partie de ces technologies utilisées quotidiennement, mais nous ne nous en rendons pas compte. Il joue un rôle essentiel dans divers domaines tels que :
Imagerie médicale
Apprentissage automatique
Réalité augmentée
Reconnaissance optique de caractères
Conception
Vente au détail
Etc. Par exemple, les caméras de circulation capables de détecter automatiquement les infractions utilisent le traitement d’images. Les résultats des appareils d’IRM et de radiographie sont améliorés grâce au traitement d’image pour les rendre plus compréhensibles. Les photographes professionnels l’utilisent pour améliorer leurs clichés et récupérer les détails perdus en raison d’une surexposition.
Il existe de nombreux exemples de ce type. En voici quelques autres pour vraiment vous montrer à quel point le traitement d’image Python est largement utilisé dans de nombreux domaines.
Les voitures autonomes utilisent le traitement d’images en temps réel pour détecter les piétons, les feux de circulation, les panneaux, les barrages routiers, etc.
Dans le commerce de détail, les systèmes de gestion des stocks et de caisse automatique utilisent le traitement d’image pour garantir qu’il n’y a pas de faux scans (par exemple, glisser une boîte vide).
Les systèmes de sécurité et de surveillance utilisent le traitement d’images en temps réel sur le flux de la caméra pour identifier les mouvements, les visages et même les mouvements de foule.
Tous ces systèmes utilisent une multitude de bibliothèques de traitement d’images Python pour remplir leurs fonctions.
La raison pour laquelle nous ne nous en rendons pas compte est que les éléments de traitement d’image sont soigneusement emballés sous la forme d’applications et de logiciels conviviaux, où le processus nous est caché.
Bibliothèques Python est couramment utilisé pour le développement de telles applications car il simplifie le processus grâce à ses bibliothèques puissantes et ses frameworks bien documentés.
Jetons un coup d’œil à quelques-unes des bibliothèques de traitement d’images les plus couramment utilisées en Python.
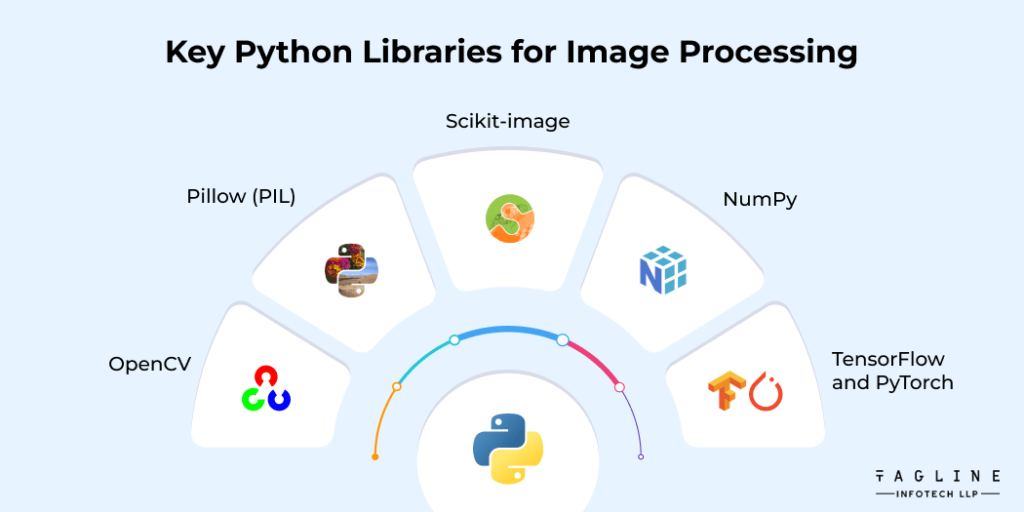
Bibliothèques Python clés pour le traitement d’images
Ce sont les bibliothèques de traitement d’images les plus populaires et les plus puissantes disponibles en Python.
OuvrirCV
OpenCV est l’une des bibliothèques les plus utilisées. Il fournit une gamme de fonctions pour l’analyse d’images, la détection de visages et la capture vidéo. Elle est très populaire car elle fonctionne rapidement et nécessite moins de programmation que les autres bibliothèques.
Oreiller (PIL)
Pillow est une bibliothèque conviviale pour la manipulation de base d’images telles que le redimensionnement, le recadrage et la conversion de format. Il est idéal pour les applications légères et les scripts d’automatisation.
Image Scikit
Scikit-image est une bibliothèque construite sur NumPy et SciPy. Il est conçu pour l’analyse avancée d’images et prend en charge des opérations telles que la segmentation, la morphologie, le filtrage et l’extraction de caractéristiques.
NumPy
Numpy est une bibliothèque de gestion de nombres. Bien qu’il ne s’agisse pas d’une bibliothèque de traitement d’images en soi, NumPy est essentiel pour gérer les données d’image sous forme de tableaux. Il constitue l’épine dorsale de calcul pour la plupart des tâches de traitement d’images.
TensorFlow et PyTorch
Ce sont des bibliothèques d’apprentissage profond et sont inestimables pour la reconnaissance d’images, la détection d’objets et le transfert de styles neuronaux. Aujourd’hui, ils alimentent de nombreuses applications visuelles basées sur l’IA.
Ces bibliothèques sont utilisées dans le développement de diverses applications, dont beaucoup sont utilisées aujourd’hui. Les programmeurs en herbe peuvent facilement apprendre à utiliser ces bibliothèques pour leurs propres applications et les expérimenter.
Intégration du traitement d’image avec d’autres outils
Les bibliothèques Python peuvent être combinées avec divers outils Web pour fournir des fonctions spécifiques ou améliorer celles existantes. Par exemple, dans un convertisseur d’image en texteune bibliothèque OCR telle que pytesseract est utilisée pour l’extraction de texte à partir d’images.
Cependant, Tesseract à lui seul n’est pas aussi précis, sauf si vous utilisez des images de très haute qualité. C’est pourquoi de nombreux programmeurs utilisent couramment OpenCV avec pytesseract pour extraire du texte lisible à partir d’images. Dans ce scénario, OpenCV est utilisé pour améliorer la qualité de l’image avant l’OCR. C’est ce qu’on appelle le prétraitement de l’image.
Dans ce code, l’image est « binarisée », c’est-à-dire un processus dans lequel la couleur de l’image est modifiée de telle sorte que le texte contraste fortement avec l’arrière-plan. Cela permet à pytesseract de reconnaître facilement les caractères et d’exécuter ses fonctions OCR avec une précision beaucoup plus élevée.
Pour ajouter plus de fonctions, vous pouvez lire la documentation sur OpenCV (ou la bibliothèque de votre choix) et découvrir les fonctions qu’il fournit. Vous pouvez ensuite les ajouter à votre pipeline de prétraitement.
L’avenir des bibliothèques Python dans le traitement d’images
L’avantage de Python est qu’il est très populaire, régulièrement mis à jour et qu’il compte une vaste communauté d’amateurs, de professionnels et de débutants. Tous l’aiment suffisamment pour créer des bibliothèques, mettre à jour les plus anciennes, créer des forks uniques de bibliothèques existantes, etc.
Ainsi, à l’avenir, Python sera toujours un acteur majeur dans le traitement d’images et évoluera avec le temps pour fournir de nouvelles fonctionnalités, améliorer les fonctions existantes et même créer des solutions prêtes à l’emploi pour divers problèmes de traitement d’images.
Voici quelques façons dont le traitement d’images en Python pourrait progresser à l’avenir.
AI Enhancement. Étant donné que Python est déjà largement utilisé pour l’apprentissage automatique, nous pouvons nous attendre à voir des bibliothèques de traitement d’images qui exploitent cette capacité pour améliorer la qualité de l’image, restaurer les détails perdus et supprimer les artefacts.
Traitement d’images 3D. Bien que les technologies actuelles de traitement d’images fonctionnent avec des images 2D, nous pouvons nous attendre, à l’avenir, à ce que les bibliothèques de traitement d’images Python gèrent également les images et les paysages 3D.
Intégration IoT. Les bibliothèques actuelles sont trop lourdes pour être exécutées sur des ordinateurs de petite taille tels que les appareils IoT. À l’avenir, nous pouvons nous attendre à ce que la taille et les exigences de calcul de ces bibliothèques diminuent afin qu’elles puissent également fonctionner sur les appareils IoT.
Ce ne sont là que quelques-unes des façons dont le traitement d’images Python peut progresser.
Conclusion
Les vastes bibliothèques de Python en font le langage de programmation incontournable pour effectuer des tâches de traitement d’images.
Que vous souhaitiez effectuer des modifications simples ou effectuer des tâches de vision par ordinateur complexes, vous pouvez compter sur ces outils/bibliothèques pour le faire. Si jamais vous rencontrez un problème, vous pouvez consulter la vaste documentation ou poser une question à l’immense communauté Python.
Si vous explorez des projets en traitement d’image, en partenariat avec un société de développement Python peut vous aider à intégrer ces bibliothèques de manière transparente dans des applications évolutives.
Cette polyvalence et ce système de support de Python garantissent sa domination continue dans les applications basées sur des images dans tous les secteurs.
FAQ
Python est populaire pour le traitement d’images en raison du grand nombre de bibliothèques qu’il fournit pour les tâches de traitement d’images. C’est également un langage de programmation très puissant avec très peu de limitations. C’est le genre de langage dont vous avez besoin pour effectuer des tâches lourdes comme le traitement d’images.
Pillow (PIL) est le meilleur choix pour les débutants car il permet des tâches simples telles que le redimensionnement, le recadrage et la conversion d’images sans configuration complexe.
Oui. Des bibliothèques telles que TensorFlow, PyTorch et OpenCV permettent l’apprentissage en profondeur et la détection d’objets, ce qui rend Python adapté à la reconnaissance d’images basée sur l’IA, ce qui lui permet d’effectuer des tâches avancées de traitement d’images.
Pillow est une bibliothèque de manipulation d’images. Il vous permet d’effectuer des tâches simples comme le recadrage, la modification des couleurs et le redimensionnement.
OpenCV est beaucoup plus avancé. Au lieu de manipuler, il se concentre sur l’analyse. Il fournit des fonctionnalités telles que la reconnaissance faciale, l’OCR et la reconnaissance de formes.
Absolument. Comme vous l’avez vu dans notre section « Intégration du traitement d’image avec d’autres outils », il est possible de combiner deux ou plusieurs bibliothèques différentes, par exemple OpenCV et pytesseract.
Accueil >> Python >> Quelle est la meilleure façon de formater le code Python ?
Dernière mise à jour : 3 juillet 2025,5 minutes de lecture
Écrire du code Python ne consiste pas seulement à le faire fonctionner correctement ; il s’agit plutôt de créer des informations claires, lisibles et maintenables. programmation lignes. Pour que les autres (y compris vous) puissent le comprendre facilement.
La façon dont le code Python est formaté joue un rôle central pour obtenir une bonne clarté. Cependant, il y a un problème : il devient très difficile de garantir un bon formatage tout en écrivant le code en même temps.
Ainsi, la seule option qui reste est d’écrire d’abord le code, et une fois terminé, de commencer à effectuer le formatage. Cela prendra du temps et des efforts précieux… n’est-ce pas ? Nous savons!
C’est pourquoi nous avons trouvé la meilleure façon de formater le code Python.
Le moyen rapide et efficace de formater le code Python
La meilleure façon de formater rapidement et précisément le code Python consiste à utiliser des formateurs Python. Il s’agit d’outils en ligne spécialement conçus pour formater et embellir le contenu donné. code de manière claire et lisible tout en préservant la fonctionnalité première.
N’oubliez pas que ces outils n’apportent aucune modification (ajout ou suppression de quelque chose) au code. Au lieu de cela, ils organisent simplement le code avec des sauts de ligne et un espacement appropriés.
Dans la section ci-dessous, nous avons discuté d’une procédure pratique pour formater le code Python à l’aide de tels outils.
Procédure étape par étape que vous devez suivre
Le processus est très simple ; il vous suffit de suivre attentivement les étapes ci-dessous.
1. Trouvez un formateur Python fiable
Tout d’abord, vous devez explorer le monde en ligne pour trouver et choisir le meilleur formateur Python. Il existe une grande variété d’embellisseurs Python disponibles en ligne, ce qui peut rendre difficile l’identification du bon.
Alors, pour vous aider, voici quelques facteurs essentiels auxquels vous pouvez envisager de prêter attention :
Pensez au classement : Choisissez un outil qui figure dans les meilleurs résultats de recherche Google, de préférence dans le top 3. En effet, les sites Web bons et fiables sont généralement bien classés.
Offre des installations de base : Optez pour un formateur Python doté des fonctionnalités de base. Par exemple, vous devriez avoir la possibilité de modifier sur place les résultats d’entrée et de sortie. De plus, l’outil doit mettre en évidence le texte du code dans différentes couleurs pour une meilleure compréhension, vous donnant la sensation d’un éditeur de code.
Aucune limitation : Enfin, optez pour une solution qui n’a aucune limitation, notamment concernant la longueur du code Python.
Ainsi, en prenant ces facteurs en considération, vous serez en mesure de choisir un outil de formatage Python fiable.
2. Entrez le code et démarrez le processus de formatage
Une fois que vous avez trouvé l’outil, il est temps d’y saisir simplement le code Python. Cela peut être fait soit en collant directement le code, soit en téléchargeant le fichier depuis le stockage local.
Pour vous montrer comment cela fonctionne, nous utiliserons Formateur Python dans les démonstrations suivantes.
Maintenant, insérons le code suivant dans cet outil.
# Sample Python code
def get_todos():
todos = [
{"userId": 1, "id": 1, "title": "delectus aut autem", "completed": False},
{"userId": 1, "id": 2, "title": "quis ut nam facilis et officia qui", "completed": False},
{"userId": 1, "id": 3, "title": "fugiat veniam minus", "completed": False}
]
return todos
if __name__ == "__main__":
print(get_todos())
Après avoir saisi le code, voici à quoi ressemble maintenant l’interface de l’outil :
Maintenant, appuyez sur le “Embellir” pour démarrer le processus de formatage du code.
3. Obtenez les résultats de sortie
Quelques secondes après avoir appuyé sur le bouton, le formateur Python proposera une version claire, lisible et bien formatée du code saisi.
Pour référence, voici une capture d’écran du résultat que nous avons obtenu.
Quelques conseils à considérer
Lors du formatage du code Python à l’aide d’outils en ligne, vous devez suivre plusieurs conseils :
Entrez toujours un code précis : Comme mentionné précédemment, les formateurs Python ne sont que des embellisseurs ; ils ne peuvent pas compiler ou déboguer votre code pour détecter des erreurs potentielles. Donc, au cas où votre code saisi
Vérifiez le résultat avant d’accepter : Ne vous contentez pas de copier/télécharger aveuglément le code formaté et de commencer à l’utiliser. Au lieu de cela, il est suggéré de l’examiner attentivement pour déterminer s’il contient ou non des erreurs. En effet, les formateurs Python ne parviennent parfois pas à fonctionner correctement, en raison d’erreurs techniques, ce qui entraîne une sortie inexacte.
Conclusion
Il est important de garantir un code Python clair et lisible, afin que chacun puisse le consulter à l’avenir pour apporter des modifications. C’est pourquoi il est toujours essentiel de formater le code lorsque vous avez fini d’écrire. La meilleure façon d’y parvenir est d’utiliser les outils de formatage Python. Entrez simplement le code, appuyez sur le bouton et obtenez une version bien formatée en quelques secondes.
FAQ
Le formatage du code Python est un processus permettant d’organiser le code de manière claire et bien structurée tout en préservant ses fonctionnalités. Cela améliorera la lisibilité, rendant le code plus facile à maintenir et à déboguer.
PEP 8 est le guide de style officiel pour le formatage du code Python. Ce guide présente les meilleurs conseils en matière d’indentation, d’espacement des lignes, de ruptures et bien d’autres encore.
Oui, c’est possible, mais ce n’est pas recommandé. En effet, cela demandera du temps et des efforts précieux, augmentant ainsi le risque de commettre des erreurs potentielles.
Kamu pasti ingin tahu rahasia supaya bisa menuntaskan impian meraih jackpot besar hari ini, kan? Jangan khawatir, karena mesin slot gacor Hotel303 hari ini siap membantu kamu mengeksekusi kemenangan besar dengan langkah yang relatif mudah.
Di artikel ini, kita akan bongkar cara sederhana dan efektif untuk menaklukkan slot gacor hari ini, sehingga peluang mendapatkan jackpot melimpah semakin dekat dalam genggamanmu. Yuk, simak tipsnya dan mulai langkahmu menuju kemenangan besar!
Kenapa Harus Pilih Slot Gacor Hari Ini?
Mesin slot yang sedang gacor punya reputasi tinggi karena kemampuannya memberikan kemenangan beruntun dan peluang jackpot besar. Saat mesin sedang dalam kondisi gacor, keberuntungan tampaknya berpihak padamu. Jadi, jangan ragu untuk mencoba keberuntunganmu di mesin yang sedang hangat-hangatnya ini.
Alasan utama memilih slot gacor:
Peluang jackpot dan bonus aktif lebih tinggi
Memberikan kemenangan beruntun yang bikin semangat
Lebih stabil dan jarang nge-lag
Cocok buat pemain yang ingin hasil cepat dan pasti
Langkah Mudah Menang Jackpot di Slot Gacor Hari Ini
Gak perlu rumit, berikut langkah simpel yang bisa langsung kamu terapkan:
Pantau mesin yang sedang gacor: Amati mesin yang sering memberi kemenangan dan bonus. Biasanya, mesin ini menunjukkan performa baik selama beberapa waktu.
Fokus di satu mesin saja: Jangan terlalu banyak berpindah-pindah. Pilih satu mesin yang gacor dan konsistenkan permainanmu di situ.
Manfaatkan fitur bonus dan free spin: Banyak mesin gacor menawarkan fitur ini. Jangan ragu untuk memanfaatkan peluang ini sebanyak mungkin.
Tentukan batas target: Batasi modal dan target kemenangan. Kalau sudah mencapai batas, jangan dipaksa untuk terus bermain.
Main dengan santai dan disiplin: Jangan terburu-buru, nikmati prosesnya dan tetap tenang saat bermain.
Strategi Tambahan untuk Menambah Peluang Jackpot
Selain langkah-langkah di atas, kamu juga bisa terapkan strategi ini:
Gunakan taruhan kecil saat mulai: Bangun momentum dan perhatikan pola mesin.
Tingkatkan taruhan secara bertahap: Jika mesin menunjukkan tren kemenangan, perlahan tingkatkan taruhan untuk peluang jackpot lebih besar.
Bermain saat promo sedang berlangsung: Banyak situs slot menggelar promo menarik yang bisa menambah peluang menangmu.
Percaya pada insting: Kadang, feelingmu bisa menjadi penentu saat memilih mesin gacor hari ini.
Kesimpulan: Jackpot Mudah Diraih di Slot Gacor Hari Ini!
Jangan ragu untuk mencoba peruntungan di mesin slot gacor hari ini. Dengan mengikuti langkah-langkah simpel dan strategi yang tepat, peluang mendapatkan jackpot besar jadi semakin nyata. Ingat, keberuntungan sering datang saat kamu siap dan percaya diri.
Ayo, manfaatkan peluang ini, pilih mesin gacor favoritmu, dan buktikan sendiri betapa mudahnya menangkan jackpot hari ini! Semoga keberuntungan selalu menyertai perjalananmu dan jackpot besar jadi milikmu.
Selamat mencoba dan semoga keberuntungan selalu menyertai langkahmu!
Les entreprises sont confrontées à une époque où la vitesse, la personnalisation et le service permanent définissent le succès de la communication client. Les systèmes obsolètes ne peuvent pas répondre à ces exigences, c’est pourquoi les gens ont commencé à opter pour des technologies avancées telles que la téléphonie cloud. En tant qu’alternative plus intelligente et évolutive, les sociétés de téléphonie cloud exploitent un large créneau allant de la sensibilisation commerciale au support client et à l’automatisation du marketing. Si vous explorez ces technologies, il est également important de comprendre les avantages et inconvénients du cloud computing pour prendre des décisions éclairées pour votre entreprise.
Mais avec des dizaines d’éditeurs de logiciels de téléphonie cloud, comment choisir le bon ?
À première vue, vous pourriez penser qu’ils ont des résultats similaires et sont construits de la même manière, mais ce n’est pas le cas. Ils diffèrent les uns des autres en ce qui concerne le traitement des appels, leur suite d’outils et les résultats plus que tout.
Dans ce blog, décomposons les cinq fonctionnalités essentielles à rechercher pour investir dans le meilleur logiciel de téléphonie cloud qui fait bouger les choses.
Que rechercher dans un logiciel de téléphonie cloud
Comme nous en avons discuté précédemment, la véritable différence entre les différentes solutions de téléphonie cloud réside dans leur gestion des appels, leur évolutivité, leurs avancées telles que les fonctionnalités d’IA et leur adaptabilité pour s’intégrer à votre pile technologique existante. Nous les examinerons en détail :
1. Routage avancé des appels : En matière de communication professionnelle, chaque appel ou chat manqué peut être une opportunité manquée. C’est là que le routage intelligent des appels aide les entreprises grâce à des fonctionnalités avancées telles que les agents persistants, la logique de repli et les options logicielles IVR. Ces piles garantissent que la communication client parvient plus rapidement au bon agent ou au bon service et répond à ses exigences.
Les avantages réels du routage avancé des appels ne se limitent pas à la résolution des requêtes, mais s’étendent à une plus grande satisfaction client et à une réduction des escalades. De plus, lorsque vous êtes équipé d’une solution de téléphonie cloud dotée des fonctionnalités mentionnées ci-dessus, votre système de communication s’appuiera sur une logique basée sur les données pour acheminer automatiquement les appels en fonction de l’heure, de la disponibilité des agents, de l’historique des appelants ou du service.
Imaginez que votre entreprise mène une campagne d’assistance, de collecte ou d’arrivée ; cette fonctionnalité réduira les frictions et vous aidera à répondre à chaque point de contact.
2. Automatisation du flux de travail : Le plus grand défi auquel les entreprises sont désormais confrontées réside dans les délais impartis pour gérer toutes les interactions avec les clients. Les tâches répétitives comme la numérotation des leads, les suivis, la mise à jour des résultats des appels, etc. ralentissent votre équipe et la détournent de tâches plus complexes. La téléphonie cloud résout ce problème grâce aux fonctionnalités d’automatisation, telles que le déclenchement d’actions telles que des alertes SMS ou WhatsApp, des mises à jour CRM et même le routage automatique basé sur la disposition des appels. Parallèlement à l’automatisation, des fonctionnalités avancées d’IA telles que l’analyse post-appel présenteront également une image complète de tous les appels, vous permettant de prendre la bonne décision concernant l’appel.
Ces caractéristiques atténuent les efforts manuels et garantissent qu’aucun appel client n’est à la traîne. De plus, les plateformes SaaS first utilisent des API et des webhooks pour intégrer cette automatisation directement dans les outils métier existants, permettant ainsi l’action requise sans aucune intervention d’agent.
3. Intégration CRM : Parlons d’un autre facteur majeur qui détruit la productivité des agents, à savoir le changement de plate-forme et d’outils pour gérer et suivre les données d’appel. Ici, un système de téléphonie cloud robuste vous aide à unifier tous les canaux de communication requis sur une seule plate-forme et s’intègre de manière transparente à votre CRM. Cette approche omnicanale aide votre entreprise à capturer les données des appels, à enregistrer les interactions et à mettre à jour automatiquement les statuts des prospects ou des tickets.
L’intégration CRM et l’approche omnicanal vous feront gagner beaucoup de temps et fourniront à l’équipe le contexte complet de l’interaction client.
4. Analyses et rapports en temps réel : Les décisions commerciales modernes s’appuient toutes sur des données appropriées, et les décisions fondées sur les données jouent un rôle majeur lorsqu’il s’agit d’interaction entreprise-client et vice versa. Équipées d’un tableau de bord d’analyse en temps réel, les communications cloud modernes aident les entreprises à obtenir des informations précises sur le volume d’appels, les résultats, les performances des agents, etc.
Dans le contexte d’une entreprise, cette fonctionnalité permet de signaler les défis, d’optimiser la planification des agents et d’améliorer les résultats des campagnes à la volée. Si vous ne pouvez pas mesurer les données, vous ne pouvez pas les améliorer.
5. Évolutivité et flexibilité : Puisque nous traversons un système de communication en constante évolution, nous devons garder notre pile de communication évolutive et adaptative. Les sociétés de téléphonie cloud permettent aux entreprises d’ajouter des utilisateurs, de lancer des campagnes simultanées, de prendre en charge facilement des équipes multisites et d’offrir de nombreuses options plus avancées pour répondre aux besoins croissants de l’entreprise.
Étant donné que la téléphonie cloud élimine les dépendances vis-à-vis du matériel physique, offre un déploiement et une intégration rapides avec des mises à niveau instantanées, votre startup à évolution rapide ou plusieurs unités commerciales peuvent en bénéficier.
Conclusion
Lorsque votre entreprise adopte un logiciel de téléphonie cloud, vous n’investissez pas seulement dans un outil pour passer ou recevoir des appels, mais vous construisez un écosystème de communication qui évolue avec l’entreprise. Cette plate-forme rapide, évolutive et intelligente offre diverses fonctionnalités et s’appuie désormais également sur l’intelligence artificielle.
Si votre entreprise envisage d’investir dans la bonne plate-forme pour façonner vos interactions avec vos clients et convertir les clients de demain, recherchez les meilleures sociétés de téléphonie cloud. Et si vous envisagez également les communications sortantes automatisées, cela vaut la peine de rechercher un fournisseur de confiance. fournisseur de services de numérotation automatique comme MCUBE, qui peut se connecter sans effort à votre pile existante.